In questo periodo così florido per il settore dell’intelligenza artificiale, e più in particolare per la computer vision, si susseguono giornalmente pubblicazioni in cui si sperimentano applicazioni di modelli per la stima delle pose umane. Questo tema, sebbene possa sembrare apparentemente ristretto a specifici ambiti applicativi, in realtà trova applicazioni in svariati settori disciplinari: dalla guida autonoma al gaming, dai sistemi di sicurezza ad applicazioni sul tracciamento automatizzato del comportamento umano.
Oggi voglio descrivervi una pubblicazione che utilizza un metodo alternativo per svolgere questo tipo di identificazione.
Pubblicata da Rempe, Davis and Birdal, Tolga and Hertzmann, Aaron and Yang, Jimei and Sridhar, Srinath and Guibas, Leonidas J. all’ International Conference on Computer Vision (ICCV) di quest’anno, la ricerca illustra un approccio metodologico innovativo per la stima di pose umane con un approccio generativo espressivo basato su un conditional variational autoencoder.
Il progetto risulta supportato dal Toyota Research Institute (“TRI”) tramite il programma di finanziamento University 2.0 program, dal programma Samsung GRO, Ford-Stanford Alliance e da altre fonti universitarie.
HuMoR: come funziona
Iniziamo col dire che l’individuazione di una posa umana parte da processi prioritari di individuazione di una persona, individuazione della forma di questa persona ed individuazione di un contesto ambientale che eventualmente può occludere il soggetto in movimento.
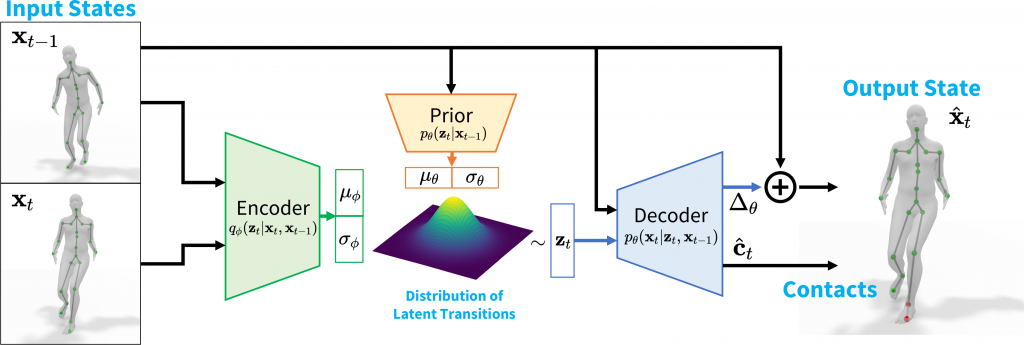
Queste procedure possono essere affrontate con metodi differenti, anche in base al tipo di input su cui stiamo lavorando (ad esempio una nuvola di punti, keypoint mocap, un semplice video, ecc.) ma conservano delle difficoltà computazionali legate alla variazione della forma umana del soggetto coinvolto e alla variabilità che questa forma umana compie durante i suoi movimenti.
L’approccio utilizzato dai ricercatori prova a risolvere queste problematiche tramite un approccio statistico, che modella una distribuzione di probabilità delle possibili transizioni di posa.
Volendo azzardare una semplificazione, si potrebbe immaginare questo approccio come un tentativo di “prevedere” le possibili pose che il soggetto potrà compiere nei fotogrammi successivi tramite l’analisi della posa attuale utilizzata da un modello predisposto in fase di training da opportuni dataset (tra cui AMASS)
I risultati presentati dal gruppo di ricerca mostrano l’utilizzo di questo algoritmo nell’individuazione di movimenti umani in video RGB-D (RGB+Depth) con parziale occlusione, riuscendo a identificare correttamente i movimenti e l’interazione tra soggetto e oggetti.
Inoltre, il modello può essere utilizzato per generare plausibili transizioni di movimenti, partendo da una pose iniziale e generando automaticamente le restanti.
La ricerca dimostra un’ottima applicabilità ed una robustezza applicativa anche in caso di zone parzialmente occluse, lasciando ottime aspettative a future implementazioni strutturate all’interno di applicativi appositi.
Per approfondire: