Con l’annuncio di Project GR00T, NVIDIA inaugura una nuova era per la robotica umanoide, introducendo una piattaforma che combina intelligenza artificiale generativa, simulazione avanzata e hardware accelerato per fornire ai robot capacità cognitive e motorie sempre più simili a quelle umane. GR00T — acronimo di Generalist Robot 00 Technology — è concepito come un foundation model destinato a servire come cervello generalista per robot umanoidi, capace di apprendere da video, istruzioni linguistiche e interazioni sensomotorie in ambienti fisici e virtuali.
Alla base del progetto c’è l’idea di un modello multimodale in grado di generalizzare il comportamento attraverso ambienti, compiti e robot differenti, analogamente a quanto fatto da foundation model nel linguaggio naturale e nella visione artificiale. L’obiettivo di NVIDIA è quello di fornire una piattaforma integrata in grado di accelerare la ricerca e lo sviluppo di robot autonomi in grado di navigare, manipolare e interagire in ambienti complessi e non strutturati.
Il framework GR00T si integra strettamente con l’ecosistema Isaac, la piattaforma NVIDIA per la robotica, e in particolare con:
Isaac Lab (per l’addestramento RL e simulato)
Isaac Sim (per la simulazione fotorealistica in Omniverse)
Isaac ROS (per l’esecuzione su robot reali).
In questo modo, NVIDIA propone una pipeline end-to-end che va dall’addestramento nel dominio simulato alla distribuzione nel mondo fisico, riducendo drasticamente il sim-to-real gap attraverso rendering avanzato, modellazione dinamica precisa e dominio adattivo.
La piattaforma è ottimizzata per girare sulla nuova generazione di moduli Jetson Thor, basati sull’architettura GPU NVIDIA Thor, capaci di eseguire modelli di AI generativa di grandi dimensioni direttamente a bordo del robot. Questo consente decisioni in tempo reale, inferenza locale e gestione di comportamenti complessi senza necessità di connessioni cloud continue — un passo cruciale per la robotica autonoma in tempo reale.
Il modello GR00T non si limita alla percezione, ma estende il suo dominio alla pianificazione motoria e alla comprensione semantica delle istruzioni, integrando moduli di NLP, Computer Vision e controllo motorio profondo. In termini pratici, questo significa che un robot addestrato con GR00T potrà, ad esempio, vedere un’azione in video e riprodurla, ricevere un comando vocale e decomporlo in sotto-azioni eseguibili, oppure apprendere nuove abilità attraverso l’osservazione.
Importanti aziende nel settore della robotica umanoide — tra cui 1X Technologies, Agility Robotics, Boston Dynamics, Figure AI, Sanctuary AI, Unitree Robotics e molte altre — stanno già collaborando con NVIDIA per l’integrazione del modello GR00T nei loro sistemi. Questo suggerisce una convergenza dell’ecosistema industriale verso standard comuni, accelerando i tempi di adozione di robot realmente autonomi in applicazioni industriali, domestiche e sanitarie.
In questo periodo così florido per il settore dell’intelligenza artificiale, e più in particolare per la computer vision, si susseguono giornalmente pubblicazioni in cui si sperimentano applicazioni di modelli per la stima delle pose umane. Questo tema, sebbene possa sembrare apparentemente ristretto a specifici ambiti applicativi, in realtà trova applicazioni in svariati settori disciplinari: dalla guida autonoma al gaming, dai sistemi di sicurezza ad applicazioni sul tracciamento automatizzato del comportamento umano.
Oggi voglio descrivervi una pubblicazione che utilizza un metodo alternativo per svolgere questo tipo di identificazione.
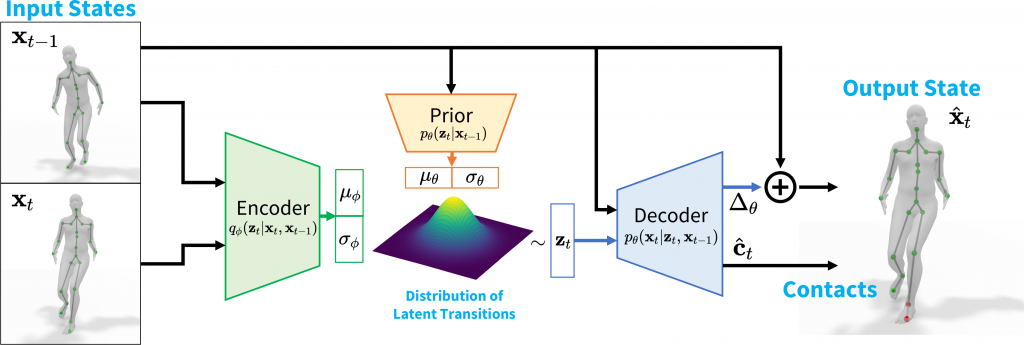
Pubblicata da Rempe, Davis and Birdal, Tolga and Hertzmann, Aaron and Yang, Jimei and Sridhar, Srinath and Guibas, Leonidas J. all’ International Conference on Computer Vision (ICCV) di quest’anno, la ricerca illustra un approccio metodologico innovativo per la stima di pose umane con un approccio generativo espressivo basato su un conditional variational autoencoder. Il progetto risulta supportato dal Toyota Research Institute (“TRI”) tramite il programma di finanziamento University 2.0 program, dal programma Samsung GRO, Ford-Stanford Alliance e da altre fonti universitarie.
HuMoR: come funziona
Iniziamo col dire che l’individuazione di una posa umana parte da processi prioritari di individuazione di una persona, individuazione della forma di questa persona ed individuazione di un contesto ambientale che eventualmente può occludere il soggetto in movimento.
Queste procedure possono essere affrontate con metodi differenti, anche in base al tipo di input su cui stiamo lavorando (ad esempio una nuvola di punti, keypoint mocap, un semplice video, ecc.) ma conservano delle difficoltà computazionali legate alla variazione della forma umana del soggetto coinvolto e alla variabilità che questa forma umana compie durante i suoi movimenti.
L’approccio utilizzato dai ricercatori prova a risolvere queste problematiche tramite un approccio statistico, che modella una distribuzione di probabilità delle possibili transizioni di posa.
Volendo azzardare una semplificazione, si potrebbe immaginare questo approccio come un tentativo di “prevedere” le possibili pose che il soggetto potrà compiere nei fotogrammi successivi tramite l’analisi della posa attuale utilizzata da un modello predisposto in fase di training da opportuni dataset (tra cui AMASS)
I risultati presentati dal gruppo di ricerca mostrano l’utilizzo di questo algoritmo nell’individuazione di movimenti umani in video RGB-D (RGB+Depth) con parziale occlusione, riuscendo a identificare correttamente i movimenti e l’interazione tra soggetto e oggetti.
Inoltre, il modello può essere utilizzato per generare plausibili transizioni di movimenti, partendo da una pose iniziale e generando automaticamente le restanti.
La ricerca dimostra un’ottima applicabilità ed una robustezza applicativa anche in caso di zone parzialmente occluse, lasciando ottime aspettative a future implementazioni strutturate all’interno di applicativi appositi.
Negli ultimi anni, con lo sviluppo e l’applicazione sempre più diffusa della metodologia BIM e, più in generale, delle tecniche di progettazione parametrica e informativa, il termine digital twin è sempre più presente e incluso nelle politiche di sviluppo digitale, soprattutto in ambito ingegneristico.
Facciamo innanzitutto una brevissima premessa. Con il termine digital twin, intendiamo una rappresentazione digitale di un elemento, un asset o un’opera, descritta nelle sue componenti formali e informative, con la caratteristica di consentire l’aggiornamento continuo dei suoi attributi. Come è facile intuire, quindi, una delle proprietà fondamentali di un gemello digitale è proprio la sua capacità di essere aggiornato e interrogato nel tempo, possibilmente da remoto. Proprio questa sua scalabilità temporale suggerisce un approccio possibilmente basato su architetture opensource, in modo da essere svincolato da policy commerciali che possono, nel tempo, limitare o rallentare la sua fruizione.
Per questa ragione, si stanno diffondendo sempre più soluzioni opensource che offrono ambienti informativi fruibili su piattaforme online, sia in ambito edile che civile. In particolare, in quest’ultimo settore, il digital-twin si pone all’interno dei normali flussi operativi, offrendo potenzialità di interrogazione progettuali o informative direttamente in loco, durante la cantierizzazione o l’utilizzo dell’opera, anche tramite tecnologie di realtà aumentata o mixed.
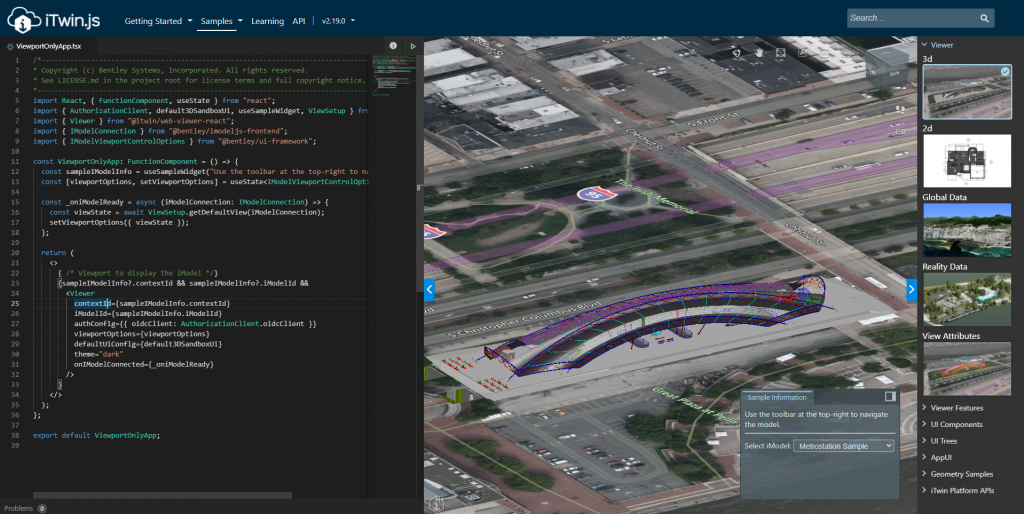
iTwin.js
Nel contesto sopra descritto, si inserisce la libreria di cui voglio parlarvi oggi. Si chiama iTwin.js, e comprende una serie di strumenti che consentono di creare la propria infrastruttura digitale per la gestione degli asset. Questi pacchetti, sviluppati in JavaScript (necessitano di supporto es2017) sono basati su tecnologie open tra cui SQLite, Node.js, NPM, WebGL, Electron, Docker, Kubernetes, e naturalmente HTML5 e CSS, consentendo quindi l’integrazione con le più comuni infrastrutture dati disponibili.
Il codice sorgente della libreria è ospitato su GitHub ed è distribuito sotto la licenza MIT.
Partendo da un rilievo fotogrammetrico o Lidar, ad esempio, è possibile utilizzare dei connectors gratuiti in grado di sincronizzare questi dati con i formati più utilizzati nel settore (ad esempio .dgn, .dwg, .rvt, .ifc, ecc.) riuscendo a diventare così un contenitore informativo fruibile da qualsiasi dispositivo.
In questo modo, il progettista può creare e personalizzare la propria infrastruttura digitale in modo da rispondere perfettamente alle proprie esigenze di controllo o interrogazione di cui necessita, adottando gli approcci di federazione che meglio discretizzano il proprio flusso lavorativo.
Con iTwin.js è possibile creare webapp, applicativi per desktop o per mobile che si interfacciano con il modello digitale ospitato all’interno della piattaforma iModelHub, da cui viene copiato ed interrogato tramite i servizi dedicati.
Quante volte ho sorriso durante la visione di alcuni film nel vedere esperti tecnologi al fianco di detective che riuscivano con pochi click a generare, partendo da un semplice fotogramma di una camera piazzata in un vicolo, un ingrandimento che trasformava magicamente un ammasso di pixel sfocati in una immagina nitida, svelando così il volto dell’assassino o la targa di un veicolo. Se fino a poco tempo fa potevano essere considerate libertà cinematografiche che rendevano più avvincente la sceneggiatura aggiungendo quel pizzico di fantasy-hi-tech che piace tanto al pubblico, oggi possiamo affermare che è diventata una applicazione possibile.
Tralasciando le applicazioni specifiche in ambito automobilistico (in cui modelli e algoritmi sono calibrati sul riconoscimento specifico di targhe di autoveicoli), uno degli approcci più condivisi fra i ricercatori si chiama Super-resolution e la troviamo, in alcune sue applicazioni primordiali, già utilizzabile all’interno di alcuni prodotti Adobe (es. Photoshop dalla versione 13.2) o di software specifici (oltre ad alcune implementazioni hardware all’interno delle GPU).La sua genesi affonda le radici in sperimentazioni e algoritmi differenti, utilizzati in ambito grafico per assolvere a esigenze differenze. All’interno dei prodotti Adobe, ad esempio, già da qualche anno troviamo la tecnologiaEnhance Details (in cui l’immagine veniva migliorata nella nitidezza e nell’aspetto cromatico, senza alterare la sua risoluzione).
Gli algoritmi di super-resolution che troviamo all’interno dei software Adobe, invece, consentono generalmente un ricampionamento lineare 2x per lato (andando così a raddoppiare la risoluzione totale per un massimo di 4x) mantenendo una migliore qualità dell’immagine rispetto all’utilizzo dei consueti algoritmi di interpolazione (es. linear, nearest-neighbor, bilinear e bicubic).
Super-resolution
La tecnologia super-resolution si basa su algoritmi di machine-learning addestrati opportunamente per interpolare i pixel aggiunti sulla base della tipologia delle forme e dell’immagine su cui viene applicata. Questo consente di evitare i consueti problemi di aliasing generati dai metodi precedenti.
Esempio di ingrandimento classico con l’utilizzo di filtri bicubico. Si noti sulla destra la presenza di aliasing che fa perdere nitidezza ai contorni. Image Credit: Masa Ushioda/Seapics/Solent News
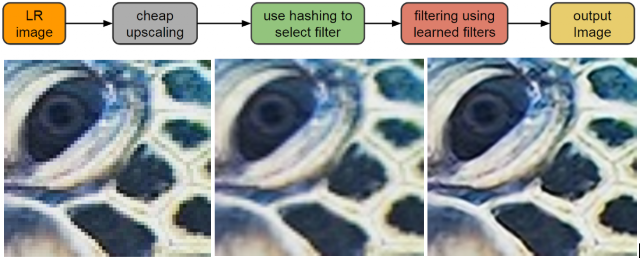
Un esempio di sperimentazione ci viene offerta da alcuni ricercatori di Google che nel 2016 hanno messo a punto un’applicazione di un modello di machine-learning chimato RAISR: Rapid and Accurate Image Super Resolution, che ha consentito di ottenere immagini ingrandite con una ottima resa qualitativa. Questo approccio ha visto la creazione di un dataset composto da 10.000 coppie di immagini (a bassa e alta risoluzione) utilizzato come training per la calibrazione del modello di machine-learning.
L’ applicazione ha permesso l’affinamento di filtri adattivi non-lineari che, applicati ad una immagine ingrandita con uno dei metodi classici di interpolazione (es. bilinear), consentono un miglioramento dei risultati rappresentativi andando ad diminuire la presenza di artefatti.
I filtri così generati, che basano la loro matematica su alcune peculiarità delle immagini (contorni, gradienti, direzione, forza, coerenza, ecc.), vengono associati tramite funzioni hash alle caratteristiche dell’immagine oggetto di ingrandimento, così da essere utilizzati nei punti e nei modi opportuni. L’immagine così elaborata viene, infine, “unita” a quella interpolata linearmente in partenza, utilizzando una funzione di media pesata, abbattendo i possibili artefatti generati dai filtri.
Workflow dell’applicazione. A sinistra l’immagine di partenza. Al centro l’immagine ingrandita con un filtro bicubico, a destra l’immagine in output dall’algoritmo RAISR.
Ma come dicevano all’inizio, i progressi nel campo dell’elaborazione di immagini sintetiche sta facendo passi da gigante, grazie anche all’integrazione di modelli sempre più complessi di machine learning all’interno dei laboratori di ricerca.
Un esempio che oggi voglio descrivere è rappresentato dal Super-Resolution via Repeated Refinements (SR3), un algoritmo sviluppato all’interno dei laboratori Google, che basa la propria funzionalità sul processo di denoising stocastico applicato al resample di un’immagine.
L’ approccio al problema è innovativo. Pur basandosi sempre su modelli di machine-learning, questo algoritmo applica il training su immagini sottoposte a noising progressivo. In questo modo il modello viene calibrato per poter essere successivamente utilizzato in modo inverso, partendo da un noising completo fino all’immagine scalata.
Questo approccio ha dimostrato ottimi risultati di benchmark nella scalatura 4x-8x soprattutto per immagini ritraenti visi umani e immagini naturali. Nell’articolo (che si può leggere tramite i riferimenti in basso), si ipotizza anche la possibilità di superare il confine degli 8x applicando più volte in cascata l’algoritmo stesso, arrivando a raggiungere fattori moltiplicativi più elevati.
E’ facile immaginare che tali applicazioni di sintesi digitale porteranno sempre più applicazioni in ambiti differenti, da quello fotografico a quello medico, consentendo magari anche il riutilizzo di video e foto registrate con apparecchiature hardware con caratteristiche e ottiche obsolete.
Ho trovato per caso questo interessante articolo pubblicato su Timing & Time Perception. Alcuni ricercatori hanno sperimentato come la percezione del tempo venga influenzata dall’utilizzo dei dispositivi di realtà virtuale. A qualcuno potrebbe risultare persino scontata come affermazione, confrontandosi magari con la reazione dei propri figli dinnanzi ad un videogame che li fa “estraniare” dal cosiddetto qui ed ora, scatenando difficili discussioni su quanto tempo sia realmente passato davanti alla console. :))
Ovviamente in questo caso leggiamo di una ricerca effettuata con criteri e metodi scientifici, in cui dei ricercatori hanno “misurato” quanto l’immersività della realtà virtuale alteri la percezione del tempo, creando quella che viene definita una compressione del tempo. Benché tale fenomeno fosse stato già affrontato in determinati ambiti specifici, in questo caso gli studiosi hanno cercato di concentrarsi sul fenomeno percettivo astraendolo dal contesto di riferimento, quindi concentrandosi proprio sulla distorsione che la nostra mente subisce con l’utilizzo di dispositivi immersivi. Chi volesse approfondire questa tematica, credo possa trovare un interessante esempio di sperimentazione in ambito medico nell’articolo Schneider, S. M., Kisby, C. K. & Flint, E. P. (2011). Effect of virtual reality on time perception in patients receiving chemotherapy. Support. Care Cancer, 19, 555–564. doi: 10.1007/S00520-010-0852-7. in cui viene osservato come l’utilizzo della realtà virtuale modifichi la percezione del tempo in pazienti oncologici sottoposti a chemioterapia sulla base di alcune variabili messe in correlazione (es. età, sesso, stato fisico, ecc.).
Come dicevamo, in questo articolo i ricercatori hanno cercato di studiare, con un approccio statistico, l’aspetto percettivo del tempo, analizzando il comportamento di diversi studenti che si sono sottoposti a questa sperimentazione, confrontandosi con la risoluzione di una sorta di labirinto 3D (creato con Unity) in modalità VR e tradizionale. Durante questa esperienza digitale, i partecipanti dovevano premere una combinazione di tasti quando pensavano fossero passati 5 minuti.
La ricerca ha portato alla luce un effettivo processo di compressione del tempo fra gli utilizzatori delle tecnologie VR. L’attribuzione di tale fenomeno, secondo gli autori, non è attribuibile a condizioni contestuali o emotivi nell’utilizzo delle apparecchiature (diciamo che l’entusiasmo dell’utilizzo dei visori VR potrebbe in qualche modo alterare la misurazione, ma in questo caso i risultati sarebbero stati opposti), quanto piuttosto ad una possibile minore percezione del proprio corpo a causa dell’isolamento a cui conduce l’immersività VR (l’utente non “vede” il proprio corpo, né il contesto ambientale e pertanto perde dei riferimenti su cui basare la propria percezione dello trascorrere del tempo).
Nello specifico, lo studio ha evidenziato che i partecipanti che hanno giocato tramite VR hanno utilizzato la simulazione per una media di 72,6 secondi in più prima di percepire il trascorrere dei 5 minuti rispetto agli altri partecipanti che hanno utilizzato un monitor tradizionale.
In attesa che nuovi ed ulteriori studi possano portare eventuali altre conferme a tale ipotesi, potremmo magari iniziare ad immaginare possibili applicazioni della VR in ambiti terapeutici e medici, in cui questa “compressione temporale” possa diventare funzionale all’attenuazione di patologie o donare sollievo durante terapie particolarmente intense.
Sappiamo che la realtà virtuale in tutte le sue declinazioni (mixed e augmented) sta subendo un ennesimo rallentamento a causa dell’ancora prematuro sviluppo tecnologico dei dispositivi di fruizione. Questi dispositivi risultano ancora costosi, ingombranti, poco performanti e non in grado ancora di azzerare gli effetti del cosiddetto motion sickness in un utilizzo continuativo. Tali limitazioni hanno portato ad un forte rallentamento nello sviluppo di applicativi, soprattutto nella parte terminale della filiera AEC, quella che riguarda la posa in opera e la cantierizzazione. Infatti, sebbene ormai assistiamo da diversi anni ad una maturazione nello sviluppo di ambienti di progettazione e fruizione immersiva (soprattutto in ambito VR), di fatto sono ancora rari i casi di utilizzo concreto da parte di imprese o gestori. Come ho avuto modo di affrontare già nel mio podcast di qualche tempo fa (ascolta il podcast), ritengo che questo limite non permetta un reale utilizzo delle potenzialità che la realtà immersiva può offrire in ambito ingegneristico, relegando tali esperienze ad eventi espositivi o workflow paralleli di veste puramente sperimentale.
https://www.youtube.com/watch?v=e8zSWXAYeIU
VisualiLive Demo. Visualizzazione armatura virtuale in cantiere
In tale contesto, viene alla luce la notizia che Unity (famoso ambiente di sviluppo di gaming) ha acquisito la società VisualLive, azienda statunitense che ha diversi anni sviluppa applicazioni di augmented e mixed reality in ambito AEC con supporto dei dispositivi Microsoft HoloLens e mobile. Questa azienda, si è concentrata sullo sviluppo di applicativi qr-code based che consentono la “sovrapposizione” di modelli ed informazioni a contesti reali tramite l’ancoraggio supportato da tecnologie di tracking e l’aggiornamento in tempo reale delle informazioni progettuali, che vengono così visualizzate dagli operatori e integrate tramite plugin all’interno di software come Revit e Navisworks. Questa acquisizione non è l’unica in casa Unity che evidenzia la rotta intrapresa dall’ambiente di sviluppo, che mira a spostare il proprio bacino di utilizzatori verso la fascia di professionisti che vogliono integrare nel loro workflow esperienze interattive, immersive ed integrate. Si può immaginare, ad esempio, la possibilità di inserire un modello BIM all’interno di uno spazio reale per valutarne la fattibilità o le interferenze con il costruito, agevolando la fase di lavorazione ai tecnici dotati di dispositivi AR/MR.
VisualLive demo
Queste integrazioni tra software, assieme allo sviluppo di nuovi dispositivi wearable più performanti, segnano in modo evidente la volontà di uno sviluppo simulativo che riesca a coprire tutti gli step di lavorazione di un progetto, dal concept alla cantierizzazione, dalla progettazione alla verifica. Solo così si potrà arrivare all’ambita integrazione virtuale che le varie software house pubblicizzano ormai da diversi anni nei loro spot. Non ci resta che attendere e…provare.
Riportare in vita foto d’epoca. Questo è il nuovo servizio pubblicato da MyHeritage che sicuramente troverà eco nei social e che susciterà la curiosità di molti appassionati. Andando sul sito https://www.myheritage.it/deep-nostalgia è possibile, dopo una registrazione gratuita, caricare una qualsiasi immagine di un volto umano (anche di nostri cari defunti…) per vederne una piccola animazione online.
Il servizio Deep Nostalgia di myheritage.it
Se tale funzionalità ha ovviamente l’obiettivo di attirare clienti al sito che riunisce appassionati di genealogia (oltre a possibili altre finalità di data recording di immagini caricate) in realtà porta alla luce del pubblico generalista una importante start-up che in questi ultimi anni ha studiato e implementato importanti algoritmi basati sul face-recognition.
Prima di introdurla, cercherò di fare una breve sintesi su un argomento sicuramente molto vasto (sia tecnicamente che eticamente) a cui però dobbiamo in qualche modo approcciarci anche per raggiungere una certa consapevolezza dei sistemi che usiamo quotidianamente.
Face recognition e privacy
Con la diffusione sempre più capillare delle tecniche di face recognition applicate nei settori più disparati, si sta portando alla luce una problematica legata alla conservazione e all’utilizzo di questi dati biometrici conservati dalle società fornitrici di servizi che, se non utilizzati in modo appropriato, possono diventare materiale utile per il tracciamento e il furto della nostra identità. Per sottolineare l’importanza della conservazione di tali dati, basti immaginare che, a differenza di altri sistemi di controllo di accesso, in caso di violazione e compromissione dei nostri dati biometrici, questi non non possono essere modificati o azzerati, come avverrebbe in caso di semplici password.
Ma pensiamo anche i servizi non prettamente legati all’autenticazione, come ad esempio le applicazioni di smart-cities, traffic monitoring, telecamere di video-sorveglianza, ecc. Tutte queste fonti di registrazione riversano il loro flusso dati in archivi digitali che, giorno per giorno, conterranno migliaia, anzi milioni, di dati biometrici di persone che sono state – a volte addirittura a loro insaputa – registrate (e quindi potenzialmente identificabili). Considerato questo contesto, le varie policy internazionali (fra cui il nostro GDPR) stanno includendo maggiore tutela e consapevolezza per questa tipologia di dati, classificandoli in sezioni specifiche all’interno dei propri regolamenti, cercando di dare massima tutela proprio a causa della natura fortemente personale di tali informazioni.
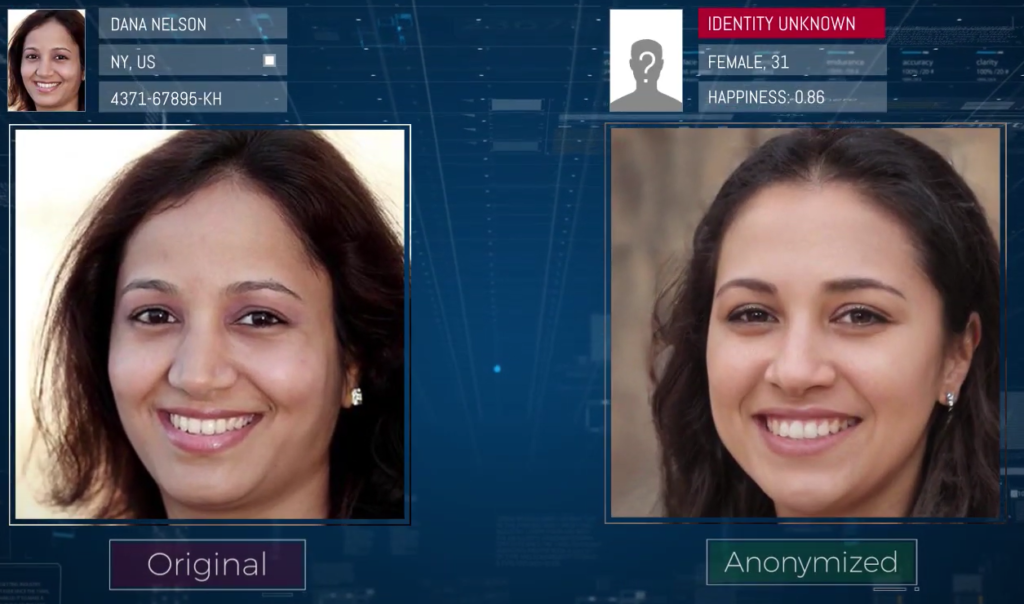
Tra le varie società che operano in questo contesto, troviamo una società israeliana chiamata D-ID che ha concentrato il suo core-business proprio sullo studio di algoritmi di anonimizzazione biometrica e in particolare implementando tecniche di de-Identification basate sul face-recognition.
Le due foto, pur sembrando del tutto identiche, vengono riconosciute dagli algoritmi di face-recognition come differenti
A differenza delle altre tecniche generalmente utilizzate in tal senso, che vanno ad operare una vera e propria alterazione o cancellazione dei volti registrati (utilizzando le tecniche di blurring, pixelation, face swapping, deterioration, quality reduction and K-SAME), la società D-ID ha concepito un algoritmo che consente di mantenere intatta la riconoscibilità e l’espressività dei volti andando, al tempo stesso, a modificare solo quelle specifiche features che vengono utilizzate dagli algoritmi di face-recognition per distinguere le immagini e ricondurle alla nostra identità, producendo di fatto un’anonimizzazione digitale.
Questo approccio può essere utilizzato anche per generare degli avatar che, pur garantendo una verosimiglianza con il nostro volto originale, non consentono ai software di dedurre le nostre informazioni biometriche, la nostra etnia, provenienza o qualsiasi altra informazione riconducibile alla nostra identità (personally identifiable information). D-ID è una delle realtà che è sotto i riflettori sia perché conta al proprio interno un advisory board di nomi illustri che possono indirizzare opportunità verso lo sviluppo di nuovi algoritmi, sia perché tali applicazioni troveranno sempre più integrazione all’interno della nostra quotidianità digitale e reale.
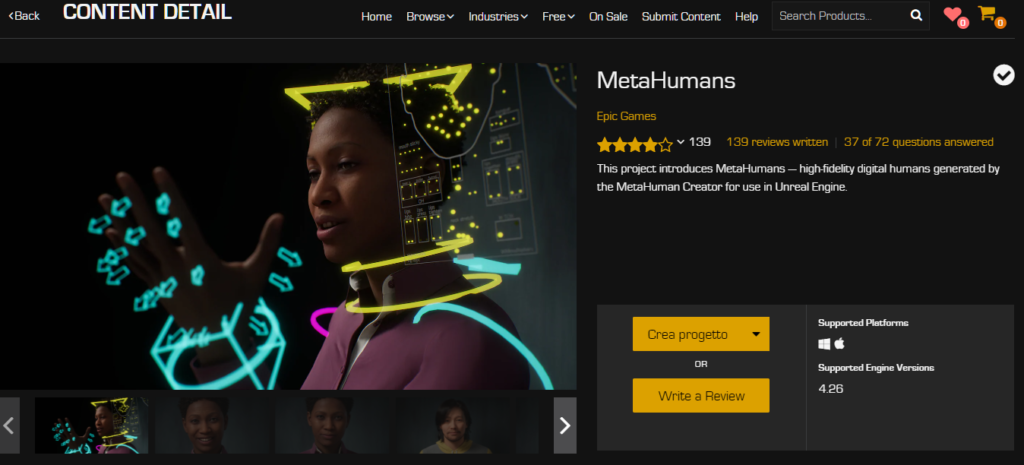
All’annuncio della nuova piattaforma di creazione e rigging MetaHuman, Epic ha deciso di anticipare la distribuzione della parte Creator con un progetto demo in Unreal in cui è possibile trovare due personaggi già realizzati. Ho provato a configurare FaceLink per tracciare il mio volto e associarlo ai personaggi MetaHuman presenti.
Requisiti:
Windows 10, build 1902 or sup con supporto a DirectX 12
Scheda video NVIDIA con supporto al Raytracing in realtime
Unreal Engine 4.26.1 o sup.
Telefono IPhone X o sup.
App FaceLink
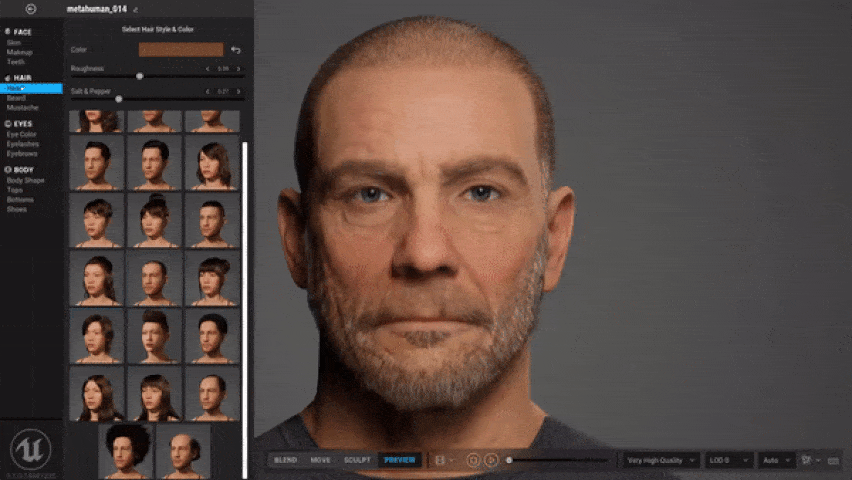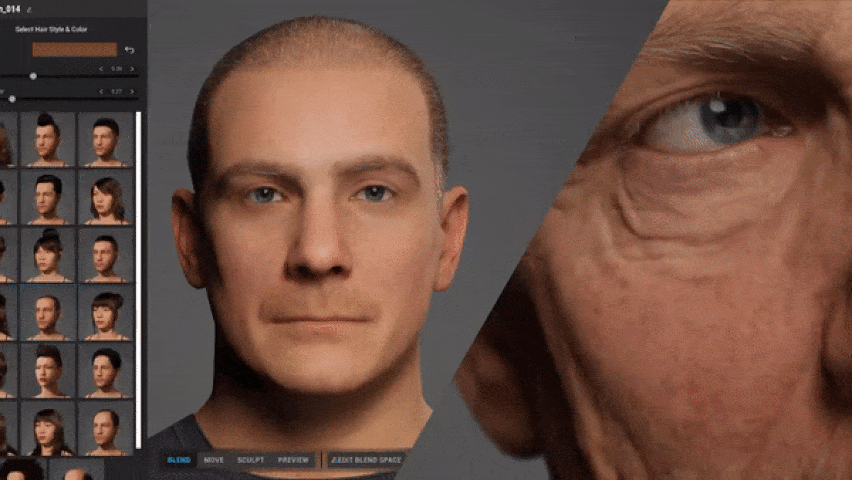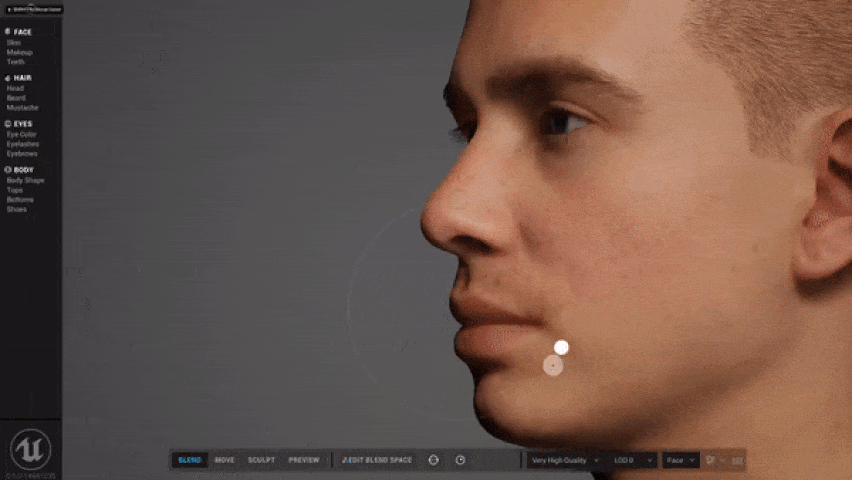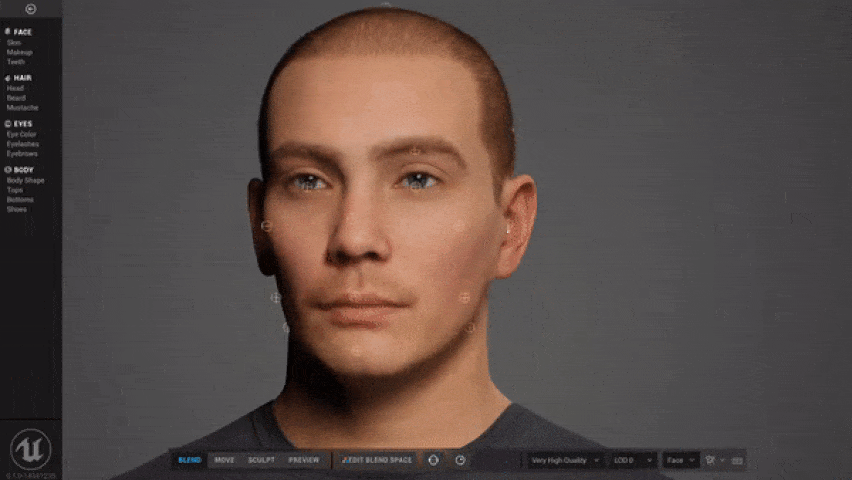
MetaHuman è una nuova piattaforma cloud creata che permette la creazione parametrica di personaggi e il loro successivo RIG, rendendoli pronti per essere utilizzati all’interno dell’ambiente di sviluppo Unreal Engine. L’utilizzo dell’app, verrà gestita tramite un collegamento web basato sul protocollo Unreal Engine Pixel Streaming e consentirà la creazione di nuovi personaggi tramite la parametrizzazione dei tratti somatici che andranno a scolpire la mesh tridimensionale del volto. In questo modo, si potrà osservare in tempo reale la modifica che tali impostazioni portano al personaggio.
Gli utenti saranno in grado di applicare stili di capelli, utilizzare campionari di abbigliamento preconfigurato e 18 tipologie di normotipo corporali. Inoltre, il Creator gestirà in modo automatica la generazione dei vari LOD variabile in base alle componenti (ad esempio il volto supporto fino a 8 LOD mentre il corpo 4 LOD configurati tramite il componente LOD sync di UE4).
Quando terminato l’asset, si potrà scaricare tramite Quixel Bridge, il tutto già completamente riggato, con LOD già definiti e pronto all’eventuale motion capture in Unreal Engine. Sarà possibile anche utilizzare i singoli file generati in formato Maya.
Attualmente il face tracking è supportato solo tramite l’app FaceLink, ma Epic promette una prossima integrazione con Faceware, JALI Inc., Speech Graphics, Dynamixyz, DI4D, Digital Domain, and Cubic Motion, oltre ovviamente alla possibilità di registrazione manuale tramite keyframes.
Maneggiando un po’ il progetto DEMO, devo ammettere che la particolare capacità di deformazione delle mesh e l’ottima configurazione delle texture, rende il risultato veramente fenomenale, soprattutto se si pensa al risparmio di tempo che tale elaborazione, con relative pesature, accompagnano le attività di creazione e riggin dei personaggi all’interno dei software 3D.
Visto che ad oggi, l’APP di creazione non è ancora utilizzabile, mi sono concentrato sulla configurazione face tracking tramite l’app FaceLink.
FaceLink
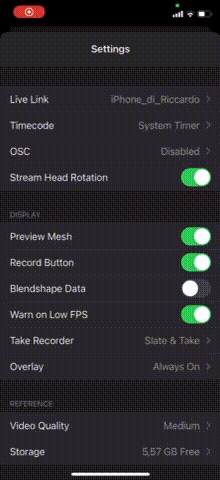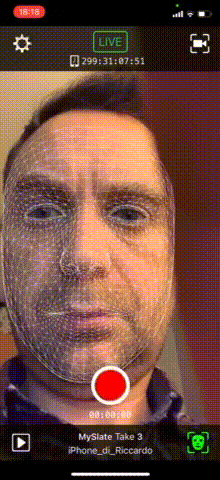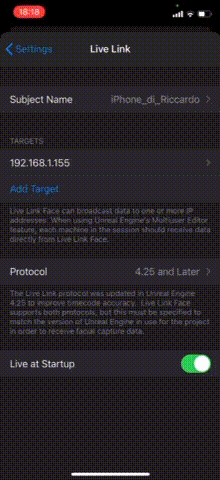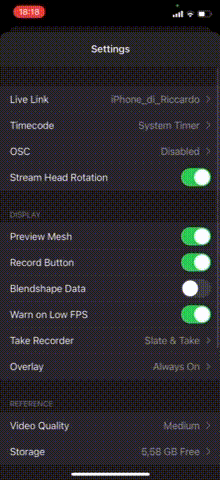
La configurazione dell’App è semplicissima. E’ sufficiente installarla ed avviarla abilitando nelle impostazioni (icona a forma di rotellina) la voce STREAM HEAD ROTATION.
Infine, sempre nelle impostazioni, cliccando sulla voce LIVE LINK possiamo accedere alle impostazioni in cui inserire l’indirizzo IP del computer sul quale è avviato Unreal Engine.
Ovviamente il computer deve condividere la stessa rete Wi-Fi del cellulare.
Per approfondire…
Se vuoi approfondire la tematica del FaceTracking markerless, puoi leggere questo mio articolo
Configurazione in Unreal Engine
Apriamo Unreal Engine, accertiamoci di avere l’ultima versione dell’Engine installato e successivamente cerchiamo nel MARKETPLACE il progetto MetaHuman, procedendo con l’installazione.
Dopo averlo installato, clicchiamo sul pulsante CREA PROGETTO, scegliamo la posizione sul nostro computer nella quale creare il nuovo progetto UE4 basato sul template MetaHumans.
A questo punto possiamo aprire il progetto appena creato e attendere qualche minuto.
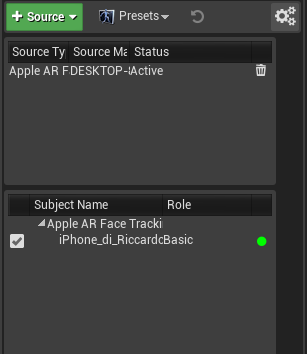
Una volta aperto Unreal, dobbiamo accedere alla finestra FaceLink (se non è visibile la possiamo abilitare dal menù Windows->FaceLink.
Se a questo punto attiviamo l’app FACELINK sul cellulare, dovremmo vedere apparire il nostro ID all’interno dell’elenco delle sorgenti. Questo significa che Unreal sta ricevendo il flusso di capturing dal nostro cellulare (ma non sa ancora a cosa attribuirlo).
In caso non compaia il nostro ID, verificare le impostazioni di firewall o antivirus presenti nel computer.
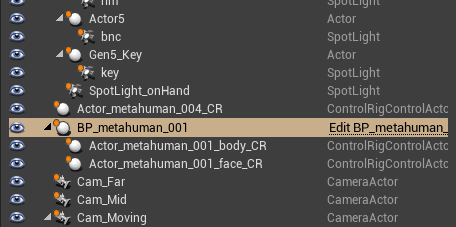
Per prima cosa, andiamo a cancellare l’oggetto METASHAPESAMPLE_SEQUENCE. Si tratta di una sequenza video dimostrativa che parte appena mandiamo in PLAY la scena.
Dopodiché, cerchiamo l’oggetto BP_metahuman_001 che identifica il blueprint associato al personaggio donna della nostra scena (si consideri che all’interno della scena, dietro un “muro” presente alle spalle del personaggio donna, si nasconde un personaggio uomo).
Nelle proprietà del componente troviamo la voce di configurazione di FaceLink. Possiamo impostare l’ID del nostro cellulare e attiviamo la voce LLINK FACE HEAD.
A questo punto possiamo attivare un PLAY SIMULATIVO (attivabile anche tramite la combinazione di tasti ALT+S) e vedremo il personaggio interpretare le nostre smorfie.
Devo dire che la facilità di configurazione del face tracking e la morbidezza espressiva dei personaggi mi ha impressionato positivamente. Qualche limite sul tracciamento con facelink lo attribuisco alla parametrizzazione standard utilizzata nel personaggio e alla tecnologia markerless che introduce inevitabilmente qualche imprecisione. Sicuramente c’è da attendere la parte Creator per poter completare la valutazione di questa nuova tecnologia ma, comunque, dobbiamo ammettere la semplificazione verso la quale si stanno spingendo i software di rigging che, salvo esigenze particolari, diventano accessibili ai più giovani progettisti 3D.
Proviamo FACEWARE, un software di Mocap markerless compatibile con le piattaforme Unity e Unreal.
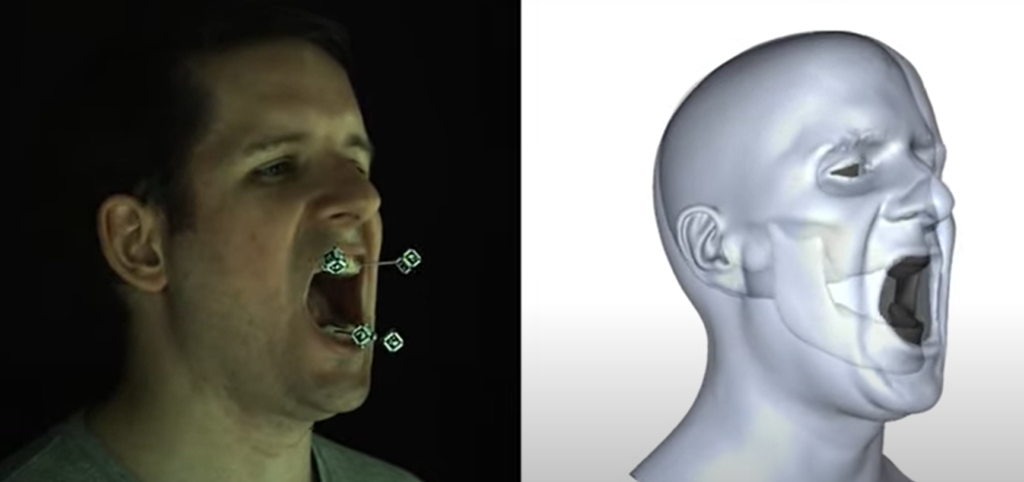
Usare in ambito “domestico” Mocap facciale oggi è sempre più comune grazie alla disponibilità di prodotti software accessibili e basati su algoritmi markeless affidabili. L’utilizzo di tecniche di tracking markless, solleva numerose problematiche di carattere tecnico-implementativo a causa delle numerose variabili (luce, ambiente, conformazione del volto, pattern recognize, ecc.) e delle difficoltà nell’interpretare movimenti muscolari interni (come la mascella). La ricerca scientifica in tale ambito sta facendo passi da gigante, grazie anche all’affinamento degli algoritmi di face-recognize (utilizzati oggi all’interno dei dispositivi mobile), all’integrazione di processi AI e alla potenza di calcolo sempre maggiore presente nei nostri computer domestici. Alcuni dei più moderni approcci in tale ambito, fa uso di dataset di ricognizioni facciali con marcatori usati come riferimento per l’implementazione di algoritmi di mappatura non-lineare delle pelle, risalendo così a “pose” di riferimento. La creazione di questi archivi, ovviamente, implica un impegno notevole al fine di ricostruire un dominio sufficiente per la ricognizione delle movimenti (si consideri che alcuni lavori di ricerca hanno addirittura costretto l’utilizzo di marker applicati sui denti per un più preciso tracciamento dei movimenti mascellari di riferimento).
from Gaspard Zoss, Derek Bradley, Pascal Bérard, and Thabo Beeler. 2018. An Empirical Rig for Jaw Animation. ACM Transactions on Graphics 37, 4 (2018), 59:1—-59:12. https://doi.org/10.1145/3197517.3201382
L’applicazione di queste tecniche trova applicazione in vari ambiti, da quello medico-scientifico (per l’identificazione e l’individuazione di deformazioni posturali e/o muscolari) all’ambito rappresentativo (ad esempio cinematografico) dove permette di creare sincronismo espressivo fra attori e personaggi digitali, facilitando la creazione di “alterego” virtuali con cui interagire in ambiente VR anche da remoto. L’utilizzo di “rig” virtuali e morph-pose digitali, stanno portando a risultati sempre più affidabili anche in contesti low-budget, con l’utilizzo di camere di media risoluzione in ambienti luminosi eterogenei.
Proviamo Faceware studio
Fra i tanti software oggi disponibili, ho voluto provato FACEWARE STUDIO, scaricabile in TRIAL dal sito https://facewaretech.com/software/studio/ Questo programma consente l’analisi in tempo reale delle deformazioni facciali senza l’utilizzo di marker e con una semplice camera (anche quella integrata nel notebook), dopo una rapidissima calibrazione iniziale.













{kind=link}