Quante volte ho sorriso durante la visione di alcuni film nel vedere esperti tecnologi al fianco di detective che riuscivano con pochi click a generare, partendo da un semplice fotogramma di una camera piazzata in un vicolo, un ingrandimento che trasformava magicamente un ammasso di pixel sfocati in una immagina nitida, svelando così il volto dell’assassino o la targa di un veicolo.
Se fino a poco tempo fa potevano essere considerate libertà cinematografiche che rendevano più avvincente la sceneggiatura aggiungendo quel pizzico di fantasy-hi-tech che piace tanto al pubblico, oggi possiamo affermare che è diventata una applicazione possibile.
Tralasciando le applicazioni specifiche in ambito automobilistico (in cui modelli e algoritmi sono calibrati sul riconoscimento specifico di targhe di autoveicoli), uno degli approcci più condivisi fra i ricercatori si chiama Super-resolution e la troviamo, in alcune sue applicazioni primordiali, già utilizzabile all’interno di alcuni prodotti Adobe (es. Photoshop dalla versione 13.2) o di software specifici (oltre ad alcune implementazioni hardware all’interno delle GPU).La sua genesi affonda le radici in sperimentazioni e algoritmi differenti, utilizzati in ambito grafico per assolvere a esigenze differenze.
All’interno dei prodotti Adobe, ad esempio, già da qualche anno troviamo la tecnologia Enhance Details (in cui l’immagine veniva migliorata nella nitidezza e nell’aspetto cromatico, senza alterare la sua risoluzione).
Gli algoritmi di super-resolution che troviamo all’interno dei software Adobe, invece, consentono generalmente un ricampionamento lineare 2x per lato (andando così a raddoppiare la risoluzione totale per un massimo di 4x) mantenendo una migliore qualità dell’immagine rispetto all’utilizzo dei consueti algoritmi di interpolazione (es. linear, nearest-neighbor, bilinear e bicubic).
Super-resolution
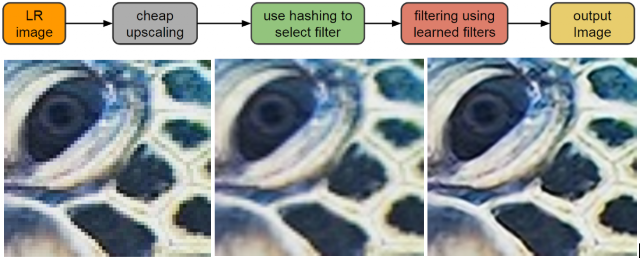
La tecnologia super-resolution si basa su algoritmi di machine-learning addestrati opportunamente per interpolare i pixel aggiunti sulla base della tipologia delle forme e dell’immagine su cui viene applicata. Questo consente di evitare i consueti problemi di aliasing generati dai metodi precedenti.

Si noti sulla destra la presenza di aliasing che fa perdere nitidezza ai contorni.
Image Credit: Masa Ushioda/Seapics/Solent News
Un esempio di sperimentazione ci viene offerta da alcuni ricercatori di Google che nel 2016 hanno messo a punto un’applicazione di un modello di machine-learning chimato RAISR: Rapid and Accurate Image Super Resolution, che ha consentito di ottenere immagini ingrandite con una ottima resa qualitativa.
Questo approccio ha visto la creazione di un dataset composto da 10.000 coppie di immagini (a bassa e alta risoluzione) utilizzato come training per la calibrazione del modello di machine-learning.
L’ applicazione ha permesso l’affinamento di filtri adattivi non-lineari che, applicati ad una immagine ingrandita con uno dei metodi classici di interpolazione (es. bilinear), consentono un miglioramento dei risultati rappresentativi andando ad diminuire la presenza di artefatti.
I filtri così generati, che basano la loro matematica su alcune peculiarità delle immagini (contorni, gradienti, direzione, forza, coerenza, ecc.), vengono associati tramite funzioni hash alle caratteristiche dell’immagine oggetto di ingrandimento, così da essere utilizzati nei punti e nei modi opportuni.
L’immagine così elaborata viene, infine, “unita” a quella interpolata linearmente in partenza, utilizzando una funzione di media pesata, abbattendo i possibili artefatti generati dai filtri.

{kind=link}
Super-Resolution via Repeated Refinements
Ma come dicevano all’inizio, i progressi nel campo dell’elaborazione di immagini sintetiche sta facendo passi da gigante, grazie anche all’integrazione di modelli sempre più complessi di machine learning all’interno dei laboratori di ricerca.
Un esempio che oggi voglio descrivere è rappresentato dal Super-Resolution via Repeated Refinements (SR3), un algoritmo sviluppato all’interno dei laboratori Google, che basa la propria funzionalità sul processo di denoising stocastico applicato al resample di un’immagine.
L’ approccio al problema è innovativo. Pur basandosi sempre su modelli di machine-learning, questo algoritmo applica il training su immagini sottoposte a noising progressivo. In questo modo il modello viene calibrato per poter essere successivamente utilizzato in modo inverso, partendo da un noising completo fino all’immagine scalata.
by Chitwan Saharia Jonathan Ho, William Chan, Tim Salimans, David Fleet, Mohammad Norouzi)

Questo approccio ha dimostrato ottimi risultati di benchmark nella scalatura 4x-8x soprattutto per immagini ritraenti visi umani e immagini naturali. Nell’articolo (che si può leggere tramite i riferimenti in basso), si ipotizza anche la possibilità di superare il confine degli 8x applicando più volte in cascata l’algoritmo stesso, arrivando a raggiungere fattori moltiplicativi più elevati.
E’ facile immaginare che tali applicazioni di sintesi digitale porteranno sempre più applicazioni in ambiti differenti, da quello fotografico a quello medico, consentendo magari anche il riutilizzo di video e foto registrate con apparecchiature hardware con caratteristiche e ottiche obsolete.
Per approfondire: