Chi studia le applicazioni di intelligenza artificiale, e più in particolare di computer vision, sa bene che uno dei limiti più importanti nella definizione e apprendimento dei modelli è la disponibilità di dataset normalizzati su cui effettuare la fase di apprendimento e testing.<!–more–>
Per questa ragione, in questo ultimo periodo, molti enti di ricerca si stanno adoperando per realizzare e mettere a disposizione del mondo scientifico tali raccolte, organizzandole su base tematica o disciplinare.
In questo contesto, è stato presentato Ego4D (Egocentric 4D Live Perception), un progetto sviluppato da Facebook insieme ad un consorzio di università internazionali, nato dalla volontà di raccogliere registrazioni video in soggettiva durante le comuni attività giornaliere.

Cosa rende originale Ego4D ?
La scelta di questo POV (point of view) nasce dal fatto che attualmente gran parte dei dataset disponibili è composto da fotografie o video riprese da punti di vista esterni al soggetto che compie l’azione, offrendo agli algoritmi la possibilità di distinguere con maggiore facilità gli elementi costituivi ed il tracking dei soggetti coinvolti.
Nei video in soggettiva, invece, la descrizione visiva di una scena o di una azione cambia totalmente, portando limitazioni e problematiche che attualmente non possono essere affrontate a causa proprio della scarsità di dataset di training.
Una delle novità di questo progetto è proprio la scelta del punto di ripresa.
Infatti, a differenza di quanto avviene normalmente con altre tipologie di raccolte video, in questo caso le registrazioni sono avvenute mediante camere indossabili, posizionate in modo da registrare secondo il punto di vista del soggetto, permettendo così di addestrare futuri modelli AI che possono coadiuvare attività umane mediante sensori “egocentrici”, capaci cioè di percepire la scena dal punto di vista dell’operatore.
Il progetto ha coinvolto oltre 850 partecipanti distribuiti in nove paesi, tra cui l’Italia ,con l’Università di Catania, preservando una eterogeneità di scenari e attività, oltre ovviamente garantendo la privacy dei soggetti ripresi.
I contesti registrati, come detto in precedenza, riguardano attività quotidiane personali (ad esempio cucinare, fare shopping, disegnare, ecc.) e professionali (es. elettricisti, muratori, cuochi, ecc.).
Tale scelta è stata motivata dalla volontà di rendere eterogeneo l’ambiente in cui si svolgono tali azioni, consentendo così che future applicazioni possano essere facilmente predisposte indipendentemente dal contesto in cui si svolgono.
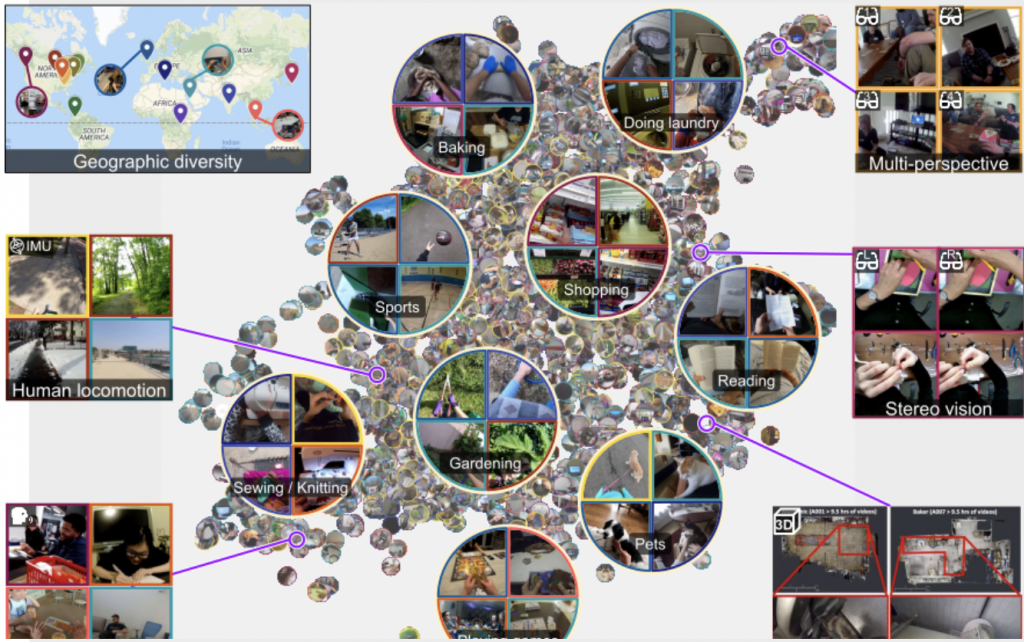
A partire dal mese di novembre 2021, il database contenente oltre 3.000 ore di video sarà reso disponibile alla comunità scientifica.
I benchmark di Ego4D
Oltre alla creazione della raccolta video, il progetto Ego4D si pone l’obiettivo di verificare 5 benchmark applicativi riguardanti i temi: interazione sociale, interazione mano-oggetto, diarizzazione audiovisiva, memoria episodica e previsione.
Questi obiettivi, rappresentano in modo chiaro la direzione della ricerca applicativa:
- la possibilità di riconoscere un’azione svolta nel passato, in modo da riconoscere e “ricordare” avvenimenti e azioni svolte
- comprendere comportamenti e abitudini, in modo da simulare previsioni sociali o sistemiche;
- apprendere i movimenti e i meccanismi che l’uomo usa per interagire con gli oggetti, in modo da interpretare gesture da integrare nei vari algoritmi;
- consentire l’utilizzo del suono in soggettiva per migliorare l’apprendimento dell’ambiente e delle azioni che si svolgono;
- studiare e comprendere l’interazione interpersonale.
L’obiettivo ultimo che si pone il progetto è quello di integrare e migliorare le potenzialità e l’integrazione della computer vision all’interno dei sistemi di automazione
Per approfondire:
Articolo





{kind=link}