Durante l’elaborazione fotogrammetrica, gran parte dei software presenti sul mercato consentono l’adozione di maschere. Queste maschere consentono di definire delle porzioni fotografiche da ignorare nei calcoli del programma. Per intenderci, se nelle immagini di una campagna di rilievo fotografico compaiono persone o autoveicoli in movimento, ad esempio, gli algoritmi SfM avranno difficoltà nella risoluzione della scena, proprio a causa del movimento che tali oggetti hanno durante le riprese (ricordiamo che, nella maggior parte delle configurazioni di ripresa, i software fotogrammetrici si basano sulla deduzione geometrica della posizione della camera rispetto ad una scena statica).
Oltre al movimento di soggetti, ci sono particolari materiali che per loro proprietà frenel comportano condizioni riflessive o di trasparenza che cambiano in base all’angolo di ripresa (ad. esempio materiali metallici, vetrature, plastiche lucide) e che quindi portano a potenziali problemi di risoluzione fotogrammetrica.
Per tutte queste ragioni, può essere utile ignorare, mascherare, delle porzioni fotografiche, andando a migliorare e facilitare i risultati dell’elaborazione fotogrammetrica.
Per creare queste maschere, i programmi fotogrammetrici offrono alcuni semplici comandi di selezione, lasciando all’utente l’onere di operare questo partizionamento manualmente per ciascuna immagine coinvolta.
In alternativa, alcuni programmi consentono anche il caricamento delle maschere tramite appositi file esterni, opportunamente realizzati tramite una logica binaria (solitamente i pixel sono identificati con colori bianco e nero). Questo approccio ha il vantaggio di consentire l’utilizzo di specifici software di fotoritocco che, per loro natura, offrono maggiori comandi di selezione che si basano su regole di contrasto o similitudine tonale o cromatica.
In questo tutorial, mostro il flusso di lavoro per creare, all’interno di Adobe Photoshop, delle maschere che vengono salvate nel canale alpha dell’immagine stessa, andando a sfruttare alcuni specifici comandi di selezione semi-automatizzata presenti all’interno del programma Adobe. Infine, all’interno di Metashape, ci occuperemo di fare leggere e assegnare automaticamente i canali alpha di ciascuna immagine caricata, facendole interpretare come maschere.
In questo VLOG, vi accompagno durante alcune fasi di un rilievo fotogrammetrico, con l’ausilio di una campagna aerea con il nostro drone DJI SPARK, fra gli ulivi secolari che segnano le splendide campagne pugliesi.
Nella fase di pre-flight, organizziamo le attività di rilievo, valutiamo gli obiettivi, le finalità e impostiamo i parametri e le modalità ottimali della campagna di volo. Queste scelte influenzeranno anche la fase di elaborazione, portando ad ottenere un prodotto fruibile per gli scopi che ci eravamo preposti, senza overloading di dati. L’elaborazione è stata effettuata con il software Agisoft Metashape 1.7.3. L’obiettivo riguardava uno studio architettonico degli edifici presenti, all’interno di una ipotesi di riprogettazione funzionale.
Quante volte ho sorriso durante la visione di alcuni film nel vedere esperti tecnologi al fianco di detective che riuscivano con pochi click a generare, partendo da un semplice fotogramma di una camera piazzata in un vicolo, un ingrandimento che trasformava magicamente un ammasso di pixel sfocati in una immagina nitida, svelando così il volto dell’assassino o la targa di un veicolo. Se fino a poco tempo fa potevano essere considerate libertà cinematografiche che rendevano più avvincente la sceneggiatura aggiungendo quel pizzico di fantasy-hi-tech che piace tanto al pubblico, oggi possiamo affermare che è diventata una applicazione possibile.
Tralasciando le applicazioni specifiche in ambito automobilistico (in cui modelli e algoritmi sono calibrati sul riconoscimento specifico di targhe di autoveicoli), uno degli approcci più condivisi fra i ricercatori si chiama Super-resolution e la troviamo, in alcune sue applicazioni primordiali, già utilizzabile all’interno di alcuni prodotti Adobe (es. Photoshop dalla versione 13.2) o di software specifici (oltre ad alcune implementazioni hardware all’interno delle GPU).La sua genesi affonda le radici in sperimentazioni e algoritmi differenti, utilizzati in ambito grafico per assolvere a esigenze differenze. All’interno dei prodotti Adobe, ad esempio, già da qualche anno troviamo la tecnologiaEnhance Details (in cui l’immagine veniva migliorata nella nitidezza e nell’aspetto cromatico, senza alterare la sua risoluzione).
Gli algoritmi di super-resolution che troviamo all’interno dei software Adobe, invece, consentono generalmente un ricampionamento lineare 2x per lato (andando così a raddoppiare la risoluzione totale per un massimo di 4x) mantenendo una migliore qualità dell’immagine rispetto all’utilizzo dei consueti algoritmi di interpolazione (es. linear, nearest-neighbor, bilinear e bicubic).
Super-resolution
La tecnologia super-resolution si basa su algoritmi di machine-learning addestrati opportunamente per interpolare i pixel aggiunti sulla base della tipologia delle forme e dell’immagine su cui viene applicata. Questo consente di evitare i consueti problemi di aliasing generati dai metodi precedenti.
Esempio di ingrandimento classico con l’utilizzo di filtri bicubico. Si noti sulla destra la presenza di aliasing che fa perdere nitidezza ai contorni. Image Credit: Masa Ushioda/Seapics/Solent News
Un esempio di sperimentazione ci viene offerta da alcuni ricercatori di Google che nel 2016 hanno messo a punto un’applicazione di un modello di machine-learning chimato RAISR: Rapid and Accurate Image Super Resolution, che ha consentito di ottenere immagini ingrandite con una ottima resa qualitativa. Questo approccio ha visto la creazione di un dataset composto da 10.000 coppie di immagini (a bassa e alta risoluzione) utilizzato come training per la calibrazione del modello di machine-learning.
L’ applicazione ha permesso l’affinamento di filtri adattivi non-lineari che, applicati ad una immagine ingrandita con uno dei metodi classici di interpolazione (es. bilinear), consentono un miglioramento dei risultati rappresentativi andando ad diminuire la presenza di artefatti.
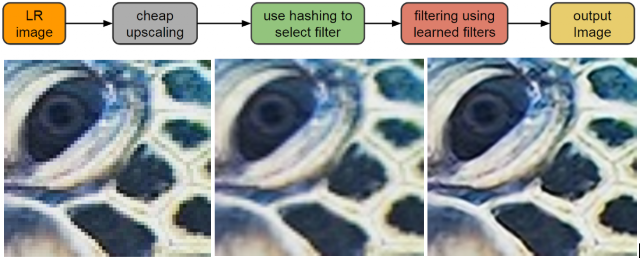
I filtri così generati, che basano la loro matematica su alcune peculiarità delle immagini (contorni, gradienti, direzione, forza, coerenza, ecc.), vengono associati tramite funzioni hash alle caratteristiche dell’immagine oggetto di ingrandimento, così da essere utilizzati nei punti e nei modi opportuni. L’immagine così elaborata viene, infine, “unita” a quella interpolata linearmente in partenza, utilizzando una funzione di media pesata, abbattendo i possibili artefatti generati dai filtri.
Workflow dell’applicazione. A sinistra l’immagine di partenza. Al centro l’immagine ingrandita con un filtro bicubico, a destra l’immagine in output dall’algoritmo RAISR.
Ma come dicevano all’inizio, i progressi nel campo dell’elaborazione di immagini sintetiche sta facendo passi da gigante, grazie anche all’integrazione di modelli sempre più complessi di machine learning all’interno dei laboratori di ricerca.
Un esempio che oggi voglio descrivere è rappresentato dal Super-Resolution via Repeated Refinements (SR3), un algoritmo sviluppato all’interno dei laboratori Google, che basa la propria funzionalità sul processo di denoising stocastico applicato al resample di un’immagine.
L’ approccio al problema è innovativo. Pur basandosi sempre su modelli di machine-learning, questo algoritmo applica il training su immagini sottoposte a noising progressivo. In questo modo il modello viene calibrato per poter essere successivamente utilizzato in modo inverso, partendo da un noising completo fino all’immagine scalata.
Questo approccio ha dimostrato ottimi risultati di benchmark nella scalatura 4x-8x soprattutto per immagini ritraenti visi umani e immagini naturali. Nell’articolo (che si può leggere tramite i riferimenti in basso), si ipotizza anche la possibilità di superare il confine degli 8x applicando più volte in cascata l’algoritmo stesso, arrivando a raggiungere fattori moltiplicativi più elevati.
E’ facile immaginare che tali applicazioni di sintesi digitale porteranno sempre più applicazioni in ambiti differenti, da quello fotografico a quello medico, consentendo magari anche il riutilizzo di video e foto registrate con apparecchiature hardware con caratteristiche e ottiche obsolete.
In questi giorni molti utenti educational stanno ricevendo un’email in cui Autodesk annuncia una nuova modalità di registrazione e assegnazione delle licenze Educational.
Con questa nuova modalità, Autodesk permette ai Docenti di assegnare le licenze educational ai propri studenti in modo centralizzato. In questo modo, si potranno indicare un massimo di 125 nominativi che saranno automaticamente assegnati come educational student, accedendo immediatamente alle licenze disponibili per i software scelti.
In questo modo, l’accesso ai software educational diventa più facile e immediato, bypassando le procedure di verifica finora necessarie per dimostrare l’eleggibilità dello status educational.
Come funziona?
Il Docente (che dovrà essere già autenticato e riconosciuto come utente educational), dopo l’accesso alla propria pagina Autodesk Educational potrà scegliere se scaricare i software disponibili come singolo utente (per il proprio utilizzo nell’ambito educativo) o gestire l’assegnazione di una classe. In quest’ultimo caso, avrà la possibilità di scegliere che tipologia di gestione vuole utilizzare, se tramite un server centralizzato di autenticazione o una più comune gestione per singolo utente, che permette a ciascun nominativo indicato di scaricare ed utilizzare sul proprio pc i programmi selezionati.
Ogni docente ha a sua disposizione 125 nominativi per ciascun software disponibile, che potrà indicare nella pagina apposita tramite i loro indirizzi email. Questi nominativi dovranno corrispondere a studenti (di età minima 13 anni), docenti o collaboratori scolastici (vedi pagina idoneità).
La funzionalità di questi abbonamenti sarà legata alla effettiva eleggibilità del docente che, come succedeva fino a poco tempo fa, deve essere rinnovata di anno in anno. E’ bene specificare, dunque, che se tale rinnovo viene interrotto o non rinnovato, tutti gli abbonamenti degli studenti associati verranno automaticamente disabilitati.
Considerato l’aggiornamento della procedura di autenticazione educational che Autodesk aveva avviato nel corso dell’anno precedente, che prevedeva una più attenta e accurata riconoscibilità dello status di studente/docente, è evidente che questa nuova procedura mira a facilitare la gestione in ambito educativo, consentendo un’attivazione centralizzata e veloce dei vari abbonamenti necessari a far lavorare una classe o un laboratorio.
E’ stato da poco pubblicato un nuovo decreto che aggiorna il Decreto Baratono (D.M. 560/2017), testo di riferimento nazionale all’adozione della metodologia BIM per gli appalti pubblici.
In questo nuovo testo, si introducono alcune definizioni che vanno meglio a definire le modalità di adozione delle procedure BIM, andando anche a chiarire le modalità di premialità previste per incentivare l’adozione di questa nuova metodologia.
Nel D.M. 560/2017 veniva specificato che le stazioni appaltanti dovevano adempiere preliminarmente alle seguenti attività:
Adozione di un piano formativo per il proprio personale coinvolto nelle procedure
Adozione di un piano di acquisizione ed organizzazione dell’infrastruttura hardware/software necessaria per la gestione dei processi BIM
L’assunzione di un atto organizzativo in cui specificare i processi di monitoraggio e gestione delle varie fasi procedurali in tutte le sue specifiche applicative.
Nel nuovo Decreto viene alleggerito tale requisito allo scopo di incentivare l’adozione sperimentale del BIM nelle pubbliche amministrazioni, prevedendo tale possibilità anche se queste non hanno ancora adottato le condizioni di cui sopra, ma le abbiano previste in una programmazione.
Come sappiamo, l’adozione del BIM ha portato notevoli stravolgimenti all’interno di enti appaltanti e studi professionali, andando spesso a ridefinire dinamiche, procedure e competenze interne. Per agevolare tale processo di adeguamento ed in considerazione anche delle forti limitazioni che il COVID ha portato all’interno dell’intero mercato, il nuovo decreto definisce una riprogrammazione delle date di adozione come segue:
1 gennaio 2022: per le opere di nuova costruzione ed interventi su costruzioni esistenti, fatta eccezione per le opere di ordinaria manutenzione di importo a base di gara pari o superiore a 15 milioni di euro;
1 gennaio 2023: per le opere di nuova costruzione, ed interventi su costruzioni esistenti, fatta eccezione per le opere di ordinaria e straordinaria manutenzione di importo a base di gara pari o superiore alla soglia di cui all’articolo 35 del codice dei contratti pubblici;
1 gennaio 2025: per le opere di nuova costruzione, ed interventi su costruzioni esistenti, fatta eccezione per le opere di ordinaria e straordinaria manutenzione di importo a base di gara pari o superiore a 1 milione di euro.
Come si nota, viene meno la soglia al di sotto del milione di euro, probabilmente in attesa di monitorare l’adozione di queste nuove procedure nel mercato e valutarne i processi attuati.
Un’altra modifica interessante introdotta dal D.M. 312/2021 riguarda la disponibilità del modello informativo dello stato di fatto, che il Decreto precedente (art. 7) prevedeva dovesse essere incluso all’interno del capitolato informativo e che ora diventa facoltativo, liberando così l’onere di una digitalizzazione del patrimonio edilizio gestito dell’ente appaltante che poteva rallentare la sperimentazione e l’adozione delle nuove procedure.
Per incentivare l’adozione del BIM, questo nuovo decreto introduce anche la possibilità di prevedere delle premialità in fase di aggiudicazione di gara, andando ad identificare quelle offerte che consentano l’integrazione dei modelli all’interno dell’infrastruttura di gestione dell’ente o tali da agevolare la tracciabilità ed il monitoraggio del ciclo di vita dell’opera.
Siamo ormai abituati agli annunci dirompenti del team Epic sulle nuove incredibili integrazioni all’interno del famoso ambiente di sviluppo Unreal Engine.
Una delle discipline in cui gli sviluppatori della casa americana stanno investendo da diverso tempo è l’integrazione del rendering in realtime in fase di produzione visiva. Ne è un esempio l’integrazione del mo-cap in tempo reale o del tracking della camera da ripresa.
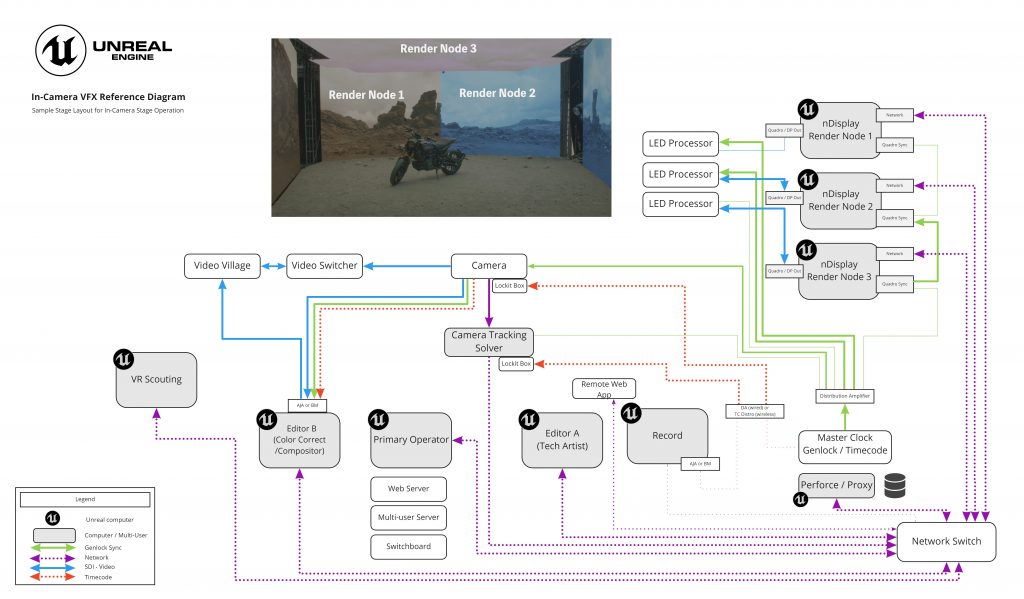
Le funzioni in-camera VFX
Immaginiamo di avere a disposizioni un set di ripresa con un background costituito da pannelli LED (come tanti monitor) collegati tra loro che proiettano un’immagine sincronizzata con la scena virtuale presente all’interno di un progetto di Unreal Engine. La camera di ripresa presente fisicamente all’interno dello stage, viene collegata ad un sistema di live tracking in modo che i suoi movimenti vengano tracciati e sincronizzati con la camera virtuale presente all’interno del progetto UE4 e visualizzata on-stage; in questo modo, la scena visualizzata sui display in background risulta perfettamente calibrata con la ripresa live simulando un inner-frustum calibrato con il FOV della camera I display esterni al campo visivo, proietteranno l’ambiente virtuale circostante, in un outer-frustum che collaborerà ad una illuminazione (e riflessione) realistica dei soggetti e dei materiali ripresi.
A questo, si aggiunge la possibilità di inserire effetti visivi all’interno della ripresa virtuale, ritrovandoli immediatamente in off-axis projection, con un perfetto allineamento con la scena reale. Grazie ai sistemi nDisplay, Live Link, Multi-User Editing, e Web Remote Control offerti da Unreal, l’utente è in grado di creare un vero e proprio set digitale virtuale.
Shooting virtuale
Ed è proprio su questa linea di sviluppo che i programmatori di Epic in collaborazione con lo studio di produzione Bullit, hanno sperimentato una piccola produzione cinematografica in virtual-real time, integrando le nuove tecnologie presenti nella versione 4.27 di Unreal Engine.
All’interno degli studi californiani della NantStudios, si è sperimentato un workflow innovativo, in cui pre-produzione, shooting e post-produzione si sono integrati all’interno di un ambiente totalmente virtualizzabile e programmabile in tempo reale. Sfruttando la potenza di calcolo di due GPU NVIDIA Quadro A6000 ed un sistema di proiezione LED dello stage virtuale, il team è riuscito a chiudere questa produzione in soli 4 giorni, sfruttando i nuovi tools di controllo e simulazione in-camera offerti dall’ambiente grafico Unreal. La possibilità di riconfigurare in pochissimo tempo una scena, simulandone configurazioni ambientali ed illuminazione, ha portato ad una notevole diminuzione dei tempi di produzione con, ovviamente, conseguente risparmio economico.
Inoltre, la possibilità di provare nuove configurazioni in realtime, ha permesso un approccio più creativo e spontaneo, facilitando la sperimentazione di nuovi setup, consentendo al regista di valutarne immediatamente la resa.
Questo nuovo paradigma di produzione porta con sè anche una rivoluzione nei flussi di lavoro normalmente configurati in una produzione; riunire sul set, durante le riprese, tutti i teams coinvolti normalmente nelle fasi di pre-produzione e post-produzione, porta ad una collaborare in tempo reale sulla scena in fase di shooting, riducendo eventuali incoerenze che normalmente possono verificarsi in fase di lavorazione non simultanea.
Un innovativo modo di concepire la produzione visiva troverà presto integrazioni sempre più diffuse nei vari ambienti di sviluppo, avvicinando settori e professionalità che normalmente sono separati in comparti differenti della computer grafica.
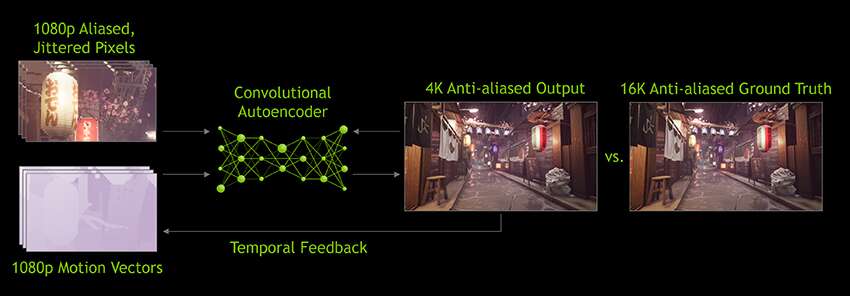
Con l’architettura Turing, NVIDIA ha iniziato ad implementare dal 2018 nuove tecnologie che sfruttano algoritmi di Intelligenza Artificiale per ottimizzare la resa qualitativa delle applicazioni e dei giochi. Una fra queste è la tecnologia DLSS, acronimo di Deep Learning Super Sampling.
Si tratta di un algoritmo implementato nel chipset NVIDIA che permette di effettuare dei calcoli di rendering con un subsampling dell’immagine, quindi ad una risoluzione inferiore, per poi rielaborarla automaticamente tramite un super-sampling effettuato internamente dai Tensor core presenti nel chip, per ottenere un’immagine ad una risoluzione maggiore, conservando una qualità ottimale ed un alto frame rate.
Ciò che differenzia questa tecnologia rispetto ai più consueti algoritmi di up-scaling, è la rete neurale profonda utilizzata internamente che, istruita dalle immagini del gioco stesso, permette una migliore calibrazione e di conseguenza una resa grafica più efficiente, specificatamente sulle features del gioco stesso.
Architettura DLSS v.2.0
In definitiva, questa strategia consente di diminuire i tempi di calcolo conservando ottime qualità visive anche alle più alte risoluzioni, con il limite, ovviamente, di richiedere alle case produttrici l’integrazione di questa funzionalità all’interno del proprio workflow (quindi solo alcuni titoli sono compatibili con il DLSS).
Nel 2020, con l’implementazione dei nuovi chipset, NVIDIA ha portato degli aggiornamenti anche a questa tecnologia (DLSS v.2.0) portando nuovi vantaggi in termini prestazionali ed implementativi.
Deliver Us the Moon – DLSS 2.0
In particolare, la fase di training della rete neurale viene in parte generalizzata sui componenti grafici più comuni all’interno dei giochi (come i sistemi particellari di fumo, fuoco, ecc.) senza la necessità quindi di ricevere un dataset di immagini specifico da ciascun produttori.
Inoltre, per i titoli che supportano questa tecnologia, è possibile impostare tre livelli di qualità computazionale: qualità, bilanciato, performance, in modo da poter impostare, sulla base delle caratteristiche hardware in possesso, un setup funzionale.
Ovviamente anche AMD è impegnata nella ricerca ed implementazione tecnologica nella pipeline di rendering dei propri chipset e al Computex 2021 ha presentato FidelityFX Super Resolution, la sua risposta al DLSS di NVIDIA (per approfondire visita il link)
Si chiama BrickIt l’app basata su algoritmi di Intelligenza artificiale che permette di fotografare i pezzi Lego a nostra disposizione e proporci delle originali idee progettuali.
Ok, so bene che in questo caso siamo ai limiti di un articolo “acchiappa click”, come quelli che si trovano spesso nelle riviste generaliste con lo scopo di incuriosire e attirare l’attenzione di un pubblico non specialista utilizzando termini iper-tecnologici per descrivere applicazioni banali. Ma, sarà forse il moodestivo o la ricerca di nuovi stimoli da parte dei piccoli di casa, ho voluto sperimentare questa nuova App che promette di automatizzare la progettazione di costruzioni Lego sulla base dei pezzi a nostra disposizione.
L’ App in questione si chiama BrickIt (brickit.app) ed è disponibile al momento solo per piattaforma iOs (iPhone) in forma gratuita. Il funzionamento è davvero semplice ed immediato: si dispongono i pezzi lego su una superficie piana (possibilmente a tinta unita), facendo attenzione a non occludere i pezzi più piccoli sotto quelli più grandi; si fotografa questa disposizione e l’app fa tutto il resto, costruendo dei veri e propri libretti di costruzione che ci guidano nella realizzazione di oggetti alternativi, tutti realizzabili con i pezzi che abbiamo fotografato.
Ma non finisce qui! Infatti durante gli step di costruzione, possiamo chiedere all’App di mostrarci l’area della fotografia in cui è presente il pezzo di cui necessitiamo, facendoci risparmiare lunghi tempi di ricerca. Tale funzionalità consente anche di scegliere, fra i pezzi presenti, delle alternative cromatiche che possiamo integrare nel progetto.
Sono consapevole che qualcuno potrebbe non apprezzare tale funzionalità, affermando che la ricerca e l’identificazione dei pezzi (come avviene per alcune tipologie di gioco, come i puzzle) rientra proprio nelle fasi creative del gioco e che quindi eliminarle altera la dinamica ludica (basti pensare quando, seguendo un libretto delle istruzioni per il montaggio e dopo una disperata ricerca di pezzi all’interno del nostro contenitore, siamo portati all’adozione di varianti , rendendo di fatto originale e unica la nostra costruzione).
Ma in questo testo vorrei soffermarmi principalmente sugli aspetti tecnologici e implementativi di questa App che dimostra come “semplici” algoritmi di matching fotografico affiancati ad un sistema di proposta progettuale possano essere coniugati in un’applicazione semplice e utile, davvero alla portata di chiunque. Il riconoscimento fotografico si basa su estrazioni di features (forma e contrasto), identificando attraverso un dizionario di immagini le varie tipologie di pezzo Lego (al momento in questo database non sono inclusi la serie Lego Technic e Lego Duplo).
Dopodiché, un modello di pattern recognition cerca in un catalogo già predisposto le occorrenze presenti, proponendoci delle alternative di costruzione, con le relative istruzioni di montaggio. Queste istruzioni si basano presumibilmente su un prontuario già presente, essendo le immagini della guida non correlate ai colori dei pezzi in nostro possesso.
Fase di sperimentazione e costruzione. 🙂
L’idea progettuale è molto simpatica ed apre ad una integrazione ludica e tecnologica comunque basata sulla socializzazione e sulle capacità di personalizzazione progettuale.
Da un punto di vista funzionale l’app si è rivelata abbastanza stabile. Durante la “sperimentazione” (con il supporto di un esperto in costruzioni ;)) l’App ha commesso pochi errori di identificazione, principalmente a causa di parziali occlusioni dei pezzi sotto altri. Tale evenienza però ha permesso piccole reinterpretazioni pesonali che hanno reso ancora più originali le nostre creazioni.
P.S.: Citazione doverosa in tale ambito è il software di progettazione sviluppato da Lego Digital Designer (https://www.lego.com/it-it/ldd) per la creazione di nuovi progetti di costruzione, con relativa elaborazione automatica di istruzioni di montaggio. In questo caso ovviamente si tratta di una semplice applicazione per la progettazione 3D senza alcun supporto di AI.
Ho trovato per caso questo interessante articolo pubblicato su Timing & Time Perception. Alcuni ricercatori hanno sperimentato come la percezione del tempo venga influenzata dall’utilizzo dei dispositivi di realtà virtuale. A qualcuno potrebbe risultare persino scontata come affermazione, confrontandosi magari con la reazione dei propri figli dinnanzi ad un videogame che li fa “estraniare” dal cosiddetto qui ed ora, scatenando difficili discussioni su quanto tempo sia realmente passato davanti alla console. :))
Ovviamente in questo caso leggiamo di una ricerca effettuata con criteri e metodi scientifici, in cui dei ricercatori hanno “misurato” quanto l’immersività della realtà virtuale alteri la percezione del tempo, creando quella che viene definita una compressione del tempo. Benché tale fenomeno fosse stato già affrontato in determinati ambiti specifici, in questo caso gli studiosi hanno cercato di concentrarsi sul fenomeno percettivo astraendolo dal contesto di riferimento, quindi concentrandosi proprio sulla distorsione che la nostra mente subisce con l’utilizzo di dispositivi immersivi. Chi volesse approfondire questa tematica, credo possa trovare un interessante esempio di sperimentazione in ambito medico nell’articolo Schneider, S. M., Kisby, C. K. & Flint, E. P. (2011). Effect of virtual reality on time perception in patients receiving chemotherapy. Support. Care Cancer, 19, 555–564. doi: 10.1007/S00520-010-0852-7. in cui viene osservato come l’utilizzo della realtà virtuale modifichi la percezione del tempo in pazienti oncologici sottoposti a chemioterapia sulla base di alcune variabili messe in correlazione (es. età, sesso, stato fisico, ecc.).
Come dicevamo, in questo articolo i ricercatori hanno cercato di studiare, con un approccio statistico, l’aspetto percettivo del tempo, analizzando il comportamento di diversi studenti che si sono sottoposti a questa sperimentazione, confrontandosi con la risoluzione di una sorta di labirinto 3D (creato con Unity) in modalità VR e tradizionale. Durante questa esperienza digitale, i partecipanti dovevano premere una combinazione di tasti quando pensavano fossero passati 5 minuti.
La ricerca ha portato alla luce un effettivo processo di compressione del tempo fra gli utilizzatori delle tecnologie VR. L’attribuzione di tale fenomeno, secondo gli autori, non è attribuibile a condizioni contestuali o emotivi nell’utilizzo delle apparecchiature (diciamo che l’entusiasmo dell’utilizzo dei visori VR potrebbe in qualche modo alterare la misurazione, ma in questo caso i risultati sarebbero stati opposti), quanto piuttosto ad una possibile minore percezione del proprio corpo a causa dell’isolamento a cui conduce l’immersività VR (l’utente non “vede” il proprio corpo, né il contesto ambientale e pertanto perde dei riferimenti su cui basare la propria percezione dello trascorrere del tempo).
Nello specifico, lo studio ha evidenziato che i partecipanti che hanno giocato tramite VR hanno utilizzato la simulazione per una media di 72,6 secondi in più prima di percepire il trascorrere dei 5 minuti rispetto agli altri partecipanti che hanno utilizzato un monitor tradizionale.
In attesa che nuovi ed ulteriori studi possano portare eventuali altre conferme a tale ipotesi, potremmo magari iniziare ad immaginare possibili applicazioni della VR in ambiti terapeutici e medici, in cui questa “compressione temporale” possa diventare funzionale all’attenuazione di patologie o donare sollievo durante terapie particolarmente intense.








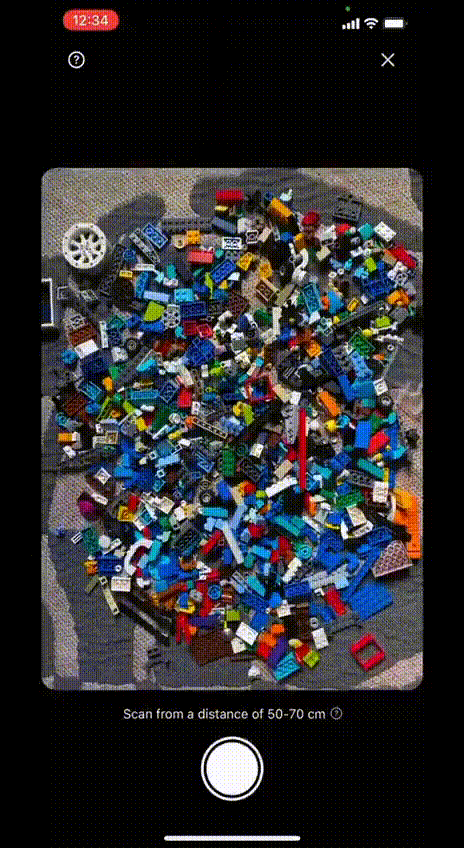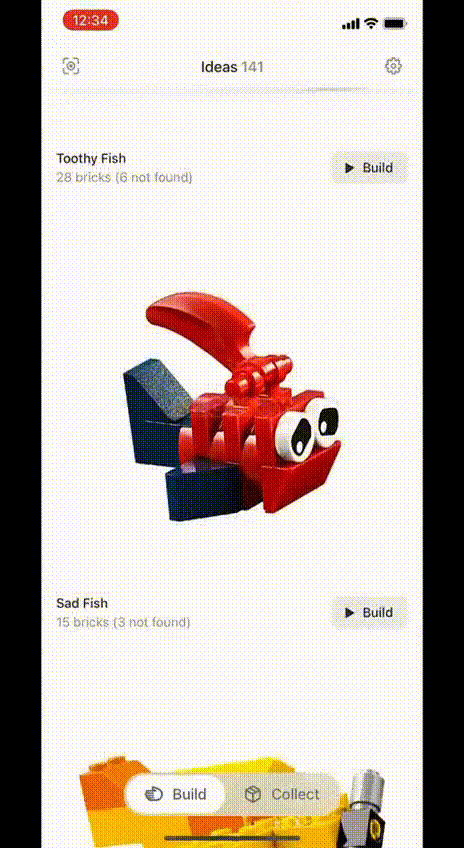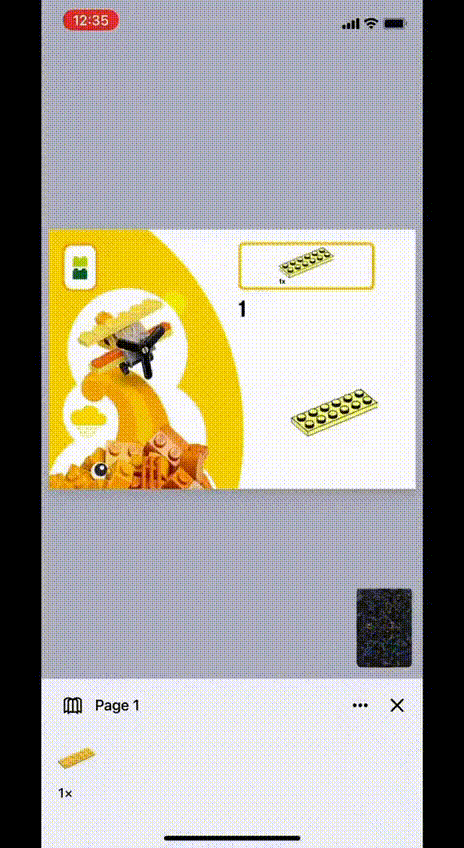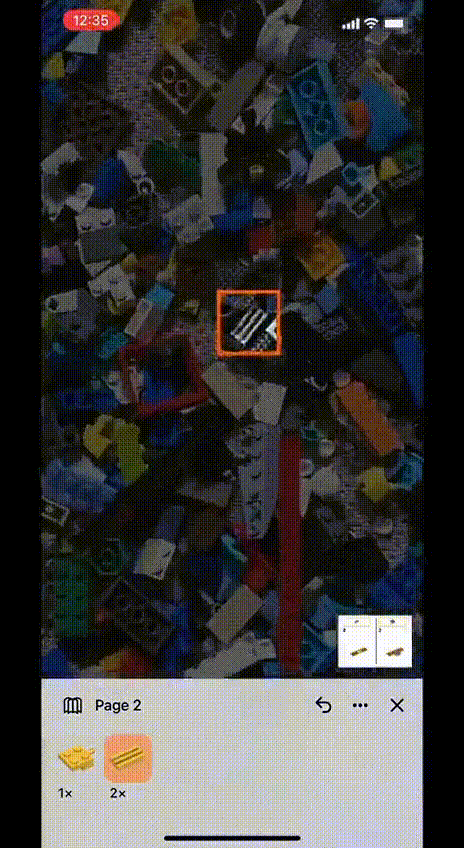



{kind=link}